基础的东西跳过
- 如果你希望为 scrapy 开启代码提示,可以在 github or gitee 搜索
- scrapy-tips
- 我通过修改了一些代码,来让 scrapy 开启了 80%的代码提示。
- 让这个好用的框架,更加好用。
2022 年 3 月 31 日,23 点 16 分
- 今天工作中遇到一个关于布隆过滤器的 Bug,我的请求明明不是重复的,总共 15 条请求,被 scrapy 过滤的剩下八条,第二次启动又剩下七条,也没有任何报错和日志输出,然后我猜测就是被过滤掉了,因为我之前就听说 Scrapy 的布隆过滤器准确率有点…..
- 然后我就为所有请求增加了
dont_filter,当然我已经处理好了程序的循环问题,否则可能陷入死循环….
2022 年 4 月 2 日,16 时 18 分
- 因为速度较慢,要求按顺序进行 URL 请求,然后我发现 Scrapy 的顺序很神奇,可能是最后一个生成的,但是会被第一个调用。
- 查了之后增加一个属性:priority
- 这个属性是一个 int 数值,数值越大,优先级越高,就可以控制请求的顺序了。
2022 年 4 月 8 日,20 时 53 分
- 今天在将一个数据
yield到管道中的时候,发现管道就是不生效 - 爬虫中间件,管道
init都生效了,就是不执行管道代码,七改八改就是不行。 - 最后发现,是我在管道中用了
yield,导致管道成为了生成器。 - 记住,只有在爬虫文件中才用 yield,在中间件,和管道等地方,都要用
return
- 今天在将一个数据
2022 年 4 月 24 日,22 点 47 分
- 当我们使用
get_stats获取爬虫运行期间的统计信息的时候,有两个时间字段和我们的时间是不一样的 - 这时候需要自己导入时间包,来增加八小时。
- stats_dict[‘start_time’] += datetime.timedelta(hours=8)
- stats_dict[‘finish_time’] += datetime.timedelta(hours=8)
- 一个是开始时间,一个是结束时间
- 当我们使用
2023 年 8 月 31 日,11:05
- 今天遇到之前的问题又不会了 这个奇葩写法
Request.replace(request, body=json.dumps({"req": encrypt_response_json}))- 当你要替换一个请求或者响应的内容的时候 就要这样写才行 注意前面的
Request是要导入的 不是实例
- 当我们希望某个中间件,或者插件 管道 在指定爬虫启动的时候才生效,可以触发一个异常
- 而不是像之前那样,在每个方法前面,都用
if判断爬虫名称是否是指定的。
@classmethod def from_crawler(cls, crawler: Crawler): if not crawler.settings.get("***", None): # 判断条件随意,只要触发了这个异常,那么中间件就不会生效 raise NotConfigured- 当我们的某一些功能,只希望在爬虫启动和关闭的时候触发某些功能,那么应该考虑的是
插件 - 通过
from_crawler绑定各种信号,而不是把他们全塞在下载中间件或者蜘蛛中间件
- 在 Scrapy 中也应该遵守代码复用的设计思想,而不是每一个爬虫独立
- 如果他们都有一个共同的请求,那么就应该将他们抽取出来,比如这样
def process_spider_output(self, response: TextResponse, result: Generator, spider: Spider): for i in result: if isinstance(i, ServerItem): # 如果是删除请求,优先级是999, 否则是6(防止出现前脚增加数据,后脚就删除的情况.) # 0优先级是只比删除请求低,比其他请求都高. priority = 666666666 if i['method'] == 'DELETE' else 6 # 在这里进行判断,增加数据到数据库 now = int(time.time() * 1000) i["data_List"]["sign"] = '***' i["data_List"]["timestamp"] = '***' yield scrapy.Request( url=i['url'], method=i['method'], body=json.dumps(i['data_List']), callback=self.server_callback, priority=priority, dont_filter=True, cb_kwargs={'logger': spider.logger} ) # 这个发送回去的请求,不要交给item continue yield i def server_callback(self, response: TextResponse, **kwargs): # 保存数据库回调,只有上面item可以调 kwargs['logger'].debug(f"{response.request.method} : {response.json()['message']}")- 以下写法统一 回调,接口参数都在爬虫中间件被拦截,进行请求,防止代码每次都出现一个没意义的复制
- 创建爬虫项目:scrapy startproject spider
- 创建普通爬虫:scrapy genspider pa www.xxx.com
- 普通爬虫创建其实是:
scrapy genspider -t basic pa www.xxx.com的简写
- 普通爬虫创建其实是:
- 创建通用爬虫:scrapy genspider -t crawl pa www.xxx.com
- 其实 Scrapy 总共有四种爬虫,可以输入:
scrapy genspider -l列出 - 创建操作 csv:
scrapy genspider -t csvfeed pa_csv www.xxx.com - 创建操作 xml:
scrapy genspider -t xmlfeed pa_xml www.xxx.com - 但大部分情况都是基本爬虫就够了。
启动多个爬虫
- 在
2.6.2版本更新之后 又支持多爬虫启动了 可以更加方便的自定义时间 参数
process = CrawlerProcess({}) # 创建进程执行对象
process.crawl(MySpider, book_name='1.xlsx', DELAY_DAY=1) # 创建爬行蜘蛛
process.crawl(MySpider, book_name='2.xlsx', DELAY_DAY=1) # 创建爬行蜘蛛
process.start() # 开始执行
process.join() # 主进程延迟 等待所有爬虫结束scrapy.crawler.CrawlerProcess实例化进程在一个进程中同时运行多个抓取爬网程序的类。CrawlerProcess必须使用dict进行实例化 就算它是空的install_root_handler是否安装根日志记录处理程序 默认值True
crawl使用提供的参数 创建爬虫crawler_or_spidercls第一个参数 指定需要启动的爬虫 后面的参数args后面的参数 根据参数名进行传递 会自动赋值给init并且你不需要自己操作init所有传入的参数 可以在爬虫内直接使用
start()开始执行所有爬虫stop()同时停止所有爬虫join()主进程等待 直到你添加的所有爬虫允许完毕好像要配置什么东西 直接启动会有问题 后面再说
- 启动爬虫:scrapy crawl pa
- 如果希望让 response 有代码提示,可以将 parse 改为以下形式 +
def parse(self, response: scrapy.http.Response, **kwargs):+ 中间件,管道等提示要改源码:https://github.com/Assistest/ScrapyTips# 导入scrapy命令行工具 from scrapy import cmdline # 通过切割执行启动指令 cmdline.execute('scrapy crawl pa'.split(' '))
快速存储和追加数据到本地
- scrapy crawl pa -O padata.json
- 可以是 JSON,XML,CSV
- 这将生成一个 padata.json 包含所有抓取项目的文件,以 JSON 序列化。
- -O 命令行开关覆盖任何现有的文件
- -o 改为使用将新内容附加到任何现有文件。
- 但是,附加到 JSON 文件会使文件内容成为无效的 JSON。附加到文件时,请考虑使用不同的序列化格式,例如 JSON Lines:
- 还没测试在大量数据的情况下,是不是存储在内存中一次写入。
- 乱码增加参数: -O data.csv -s FEED_EXPORT_ENCODING=gb18030
程序运行目录
# 当需要一个路径来执行文件的时候,可以通过配置文件读取以下路径, # 下面这个路径一直都是指向项目目录 # 路径永远是Scrapy的最外层目录... RUN_PATH = path.dirname(path.dirname(path.abspath(__file__)))
本地暂停爬虫和恢复 (推荐)在大型项目可以节省内存
- scrapy crawl pa -s JOBDIR=crawls/spider
- 后面的-s JOBDIR 表示一个目录路径,内部会存储爬虫的信息
- 下次以相同的命令启动,就会获取指定路径信息接下去爬取
- 还可以在保存爬虫运行时的状态(详见官网)
- 不过保存状态 cookie 也会失效。
- 当然你也可以使用增量爬虫(配合 redis)
自动组合 url
1.组合 url 的时候手动组合 url 非常麻烦,可以使用 scrapy 的:
- next_page = response.urljoin(next_page)
- yield scrapy.Request(next_page, callback=self.parse)
- 构建一个完整的绝对 URL
- [response.urljoin(url) for url in urls]
2.快捷请求方式:response.follow
- 上面 urljoin 还要进行一次组合,然后再次发起请求。
- response.follow:只需要给予提取到的 url,将会自动组合相对 url 进行页面请求
- response.follow_all:如果 url 获取的是一个列表可以使用这个方法
- 单个链接的直接请求:
yield response.follow(url=new_url, callback=self.parse)- 链接列表的直接请求:
yield from response.follow_all(urls=href_list, callback=self.parse)
- 终极简洁写法:
yield from response.follow_all(xpath="//div/a", callback=self.parse)- 注意,上面这种写法是因为定位到元素之后会自动拿取 href 进行拼接,所以可以这样简写,否则还是得提取。
传参的形式启动 scrapy
- scrapy crawl myspider -a http_user=myuser -a http_pass=mypassword
- 上面方法后面的-a 的所传入的属性会自动传给init构造函数,并且自动创建属性并赋值
- 在爬虫内可以使用 self.属性名进行访问
- 传参形式启动 scrapy,并且修改配置文件
- scrapy crawl myspider -s LOG_FILE=scrapy.log
- 上面的代码启动并且修改了日志文件名为 scrapy.log
allowed_domains(指定作用域)
- 一般这个属性都是被注释掉:这个属性的作用是限制 scrapy 爬取到别的网址,在 crawlspider 中比较好用
- 假设您的目标网址是https://www.example.com/1.html
- 添加’example.com’到列表中,就可以限定爬虫只能爬取这个网站的内容
custom_settings(启动修改配置文件)
- 启动修改配置文件
- 字典可以设置多个
- custom_settings = {‘LOG_LEVEL’: ‘ERROR’}
- 将需要修改的 settings 配置中的属性以字典的形式传给 custom_settings,即可修改
- 它必须定义为类属性,因为设置在实例化之前更新。
所以无法在爬虫运行的时候修改某些配置class MySpider(scrapy.Spider): name = 'myspider' custom_settings = { 'LOG_LEVEL': 'ERROR', }
爬虫日志 or 日志等级
- 配置文件中加入或者在启动时以参数的形式传入即可
- LOG_FILE=’scrapy.log’
- self.logger.info(‘’):的形式写入日志文件
- 注意 LOG_LEVEL 日志等级,低于这个日志等级并不会写入
- 存储日志文件的格式
- LOG_ENCODING
- 默认: ‘utf-8’
- LOG_STDOUT 如果为真,那所有的输出都会被输出到日志中
- 默认使用 self.logger 才会输出到日志中
- 错误等级
import logging logging.log(logging.WARNING, "This is a warning") self.logger.WARNING("This is a warning") # 输出日志,并且将日志写入本地 # 如果觉得麻烦可以重写一个函数,在内部封装好,进行输出。logging.CRITICAL - 对于严重错误(最高严重性) logging.ERROR - 对于常规错误 logging.WARNING - 警告信息 logging.INFO - 用于信息性消息 logging.DEBUG - 用于调试消息(最低严重性)
22 年 2 月 30 日更新(双日志输出):
- 上面日志配置之后,控制台的输出就没有了,非常不好用。
- 当然这也可能是你希望的。
- 如果你希望同时输出控制台,并且写入本地,可以试试以下方法…
- 当然不能 100%复原
- 在配置文件中找个位置插入下面这段代码,再次启动即可
import logging s = logging.StreamHandler() s.setLevel(level=LOG_LEVEL) s.setFormatter(logging.Formatter( "%(asctime)s [%(module)s] %(levelname)s: %(message)s", '%Y-%m-%d %H:%M:%S' )) logging.getLogger().addHandler(s)
启动-s 传参
- 以下配置可以被启动的时候传入的配置参数修改 -s
LOG_FILE:默认none,用于启动日志时候记录的文件名 如果None,将使用标准错误。 LOG_ENABLED:是否启用日志记录,默认True LOG_ENCODING:日志记录编码 默认 'utf-8' LOG_LEVEL:日志等级,默认DEBUG LOG_FORMAT:日志输出格式 默认: '%(asctime)s [%(name)s] %(levelname)s : %(message)s' 使用logging标准输出符 LOG_DATEFORMAT:日志日期输出格式,默认: '%Y-%m-%d %H : %M:%S' LOG_STDOUT:默认Flase,如果为True,您的所有输出都将出现在日志文件中(比如print('111')) LOG_SHORT_NAMES:默认为False,如果True,日志将只包含根路径。如果设置为,False 则显示负责日志输出的组件meta 内替换 IP 代理
# scrapy 代理格式如下 ip = 'http://127.0.0.1:6666' # 在任意存在meta的位置替换(前提是会走引擎)即可 request.meta['proxy'] = ip代理存放位置
- 存放在配置文件中
- 注意事项:在配置文件中存放的属性名只能是全部大写,要不然无法获取属性
- 在启动的时候需要获取配置需要有 self
# 假设在配置文件中存在如下属性: IP_LOOP = ['127.0.0.1','127.0.0.2'] # 则可以使用以下语句获取属性 self.settings['IP_LOOP'] # 并且可以通过append增加新的IP地址
- 1.1 如果不存在 self 方法,或者写在另外一个类中可以使用导入配置文件
- from spider.settings import IP_LOOP
- 并且同样可以 append
- 直接存放在爬虫创建位置(不推荐)
- 访问的时候使用 self 进行访问
class PaSpider(scrapy.Spider): name = 'pa' allowed_domains = ['www.xxx.com'] IP_LOOP = ['127.0.0.1'] start_urls = ['https://www.xxx.com/']
代理异常问题
- 当代理出现异常的时候 会根据重发次数进行重发
- 可以在以下位置进行拦截
def process_exception(self, request: Request, exception, spider: Spider):
if isinstance(exception, TimeoutError) and not request.cb_kwargs.get('is_req', False):
# 请求超时 开始重发
r = request.copy()
r.cb_kwargs['is_req'] = True
yield r传递参数:cb_kwargs
- 之前传递参数都是在 meta 中传递 item,其实在官方有指定 cb_kwargs
- cb_kwargs 是一个包含要传递给回调函数的关键字参数的字典。
- 而 meta 的作用是:
- 每个生成的链接将用于生成一个 Request 对象,该对象将在其 meta 字典中包含链接的文本

请求异常指定处理的回调函数:errback
errback ( collections.abc.Callable ) – > 如果在处理请求时引发任何异常,将调用该函数。这包括因 404 HTTP 错误等而失败的页面。
def parse(self, response): request = scrapy.Request('http://www.example.com/index.html', callback=self.parse_page2, errback=self.errback_page2, cb_kwargs=dict(main_url=response.url)) yield request # 原本回调函数正确返回的内容会回到parse_page2,如果出现错误,将会到达errback_page2 def parse_page2(self, response, main_url): pass # 如果需要获取原本会传递给parse_page2的参数,可以通过以下语句 def errback_page2(self, failure): yield dict( main_url=failure.request.cb_kwargs['main_url'], # 这条语句获取原本该传递给parse_page2的参数 )
错误状态码数据处理
- 一般情况下,scrapy 会丢弃掉错误的状态码响应,比如 404。
- 并且在正常情况下,处理错误状态码也不是一个正确的选择
- 如果你就是需要处理错误的状态码响应,可以进行以下操作。
- 以下操作之后,在回调函数就可以接受到 404 错误的网页响应。
- 正常情况下,此响应会被丢弃,除非在中间件中处理。
class MySpider(CrawlSpider): # 指定需要处理的状态码 handle_httpstatus_list = [404]
通用爬虫链接提取器
Rule( LinkExtractor(allow=r'Items/'), # 用于匹配链接的正则表达式(这个LinkExtractor的属性与下面用于Response的链接提取器一致) callback='parse_item', # 请求到页面后用于处理的回调函数(通用爬虫中不能指定parse为回调函数) follow=True, # 是一个布尔值,它指定是否应该从使用此规则提取的每个响应中跟踪链接。如果callback是 None,follow默认为True,否则默认为False cb_kwargs={'***': '***'}, # 是一个包含要传递给回调函数的关键字参数的字典。 process_links='', # 是一个可调用的,或一个字符串(在这种情况下,将使用来自具有该名称的蜘蛛对象的方法),它将为使用指定的从每个响应中提取的每个链接列表调用link_extractor。这主要用于过滤目的。 process_request='', # 是一个可调用的(或一个字符串,在这种情况下,将使用来自具有该名称的蜘蛛对象的方法),Request该规则将在每次提取时调用 该方法。这个 callable 应该将所述请求作为第一个参数Response ,并将请求发起的请求作为第二个参数。它必须返回一个 Request对象或None(以过滤掉请求)。 errback='' # 是一个可调用的函数(或者字符串),在出现异常后将会调用的一个回调函数 )
Request 请求各个参数的作用:
link_extractor:链接提取器,使用规则提取网页内链接 url( str ) 请求url,如果链接无效将会触发ValueError异常 callback 下载信息后调用的函数,如果未指定,将使用蜘蛛的 parse()方法。请注意,如果在处理期间引发异常,则会调用 errback method ( str ) 表示请求中 HTTP 方法的字符串。这保证是大写的。例如:"GET","POST","PUT" 默认为大写 meta ( dict ) –Request.meta属性的初始值。如果给定,则在此参数中传递的 dict 将被浅复制。 body ( bytes或str ) – 请求正文。如果传递了字符串,则使用encoding传递的(默认为utf-8)将其编码为字节。如果 body未给出,则存储一个空字节对象。无论此参数的类型如何,存储的最终值都将是字节对象(绝不是字符串或None)。 headers (dict) –此请求的标头。dict 值可以是字符串(对于单值标题)或列表(对于多值标题)。如果 None作为值传递,则根本不会发送 HTTP 标头。 Request 对象,该对象将在其meta字典中(在link_text键下)包含链接的文本。如果省略,将使用不带参数创建的默认链接提取器,从而提取所有链接。 encoding ( str ) -- 此请求的编码(默认为'utf-8')。此编码将用于对 URL 进行百分比编码并将正文转换为字节(如果以字符串形式给出)。 priority ( int ) – 此请求的优先级(默认为0)。调度程序使用优先级来定义用于处理请求的顺序。具有更高优先级值的请求将更早执行。允许负值以指示相对较低的优先级。(数值越大优先级越高) dont_filter ( bool ) – 表示该请求不应被调度程序过滤。当您想要多次执行相同的请求时使用它,以忽略重复项过滤器。小心使用它,否则你会陷入爬行循环。默认为False. errback ( collections.abc.Callable ) – 如果在处理请求时引发任何异常,将调用该函数。这包括因 404 HTTP 错误等而失败的页面。 flags ( list ) – 发送到请求的标志,可用于日志记录或类似目的。 cb_kwargs ( dict ) – 带有任意数据的字典,将作为关键字参数传递给请求的回调。 cookie:请求携带的cookie,可以使用两种方式。# 第一种,使用字典 request_with_cookies = Request(url="http://www.example.com", cookies={'currency': 'USD', 'country': 'UY'}) # 第二种,使用列表字典 request_with_cookies = Request(url="http://www.example.com", cookies=[{'name': 'currency', 'value': 'USD', 'domain': 'example.com', 'path': '/currency'}])
Response 各个参数的作用
url( str ) 此响应的url status 此响应的状态码(默认200 成功) headers 此响应的相应头 (可以是字符串,或者列表) body:响应正文,但要访问网页字符串,请使用:response.text(该属性是只读的。要更改响应的正文,请使用 replace().) flags ( list ) – 是一个包含Response.flags属性初始值的列表 。如果给定,列表将被浅复制。 request 生成此响应的对象。在响应和请求通过所有下载器中间件之后,在 Scrapy 引擎中分配此属性。(在中间件用于表名哪个请求生成的) certificate:代表服务器 SSL 证书的对象。 ip_address:产生响应的服务器IP地址 protocol:用于下载响应的协议 例如:“HTTP/1.0”、“HTTP/1.1”、“HTTP/2.0”
LxmlLinkExtractor 链接提取器
- 用于从 Response 中提取链接
- LxmlLinkExtractor 是推荐的链接提取器,带有方便的过滤选项。它是使用 lxml 强大的 HTMLParser 实现的。
allow:符合正则表达式的url才会被匹配(如果未给出,则会提取出所有url) deny:符合正则表达式的url才会被排除,优先级比allow高(也就是说,先用这个规则排除掉url。然后再用上面的规则进行匹配) allow_domains:单个url或者url列表,在这些列表内的url会被用于正则表达式提取规则 deny_domains:和上面相反,这些url或者列表内的不会被用于正则表达式提取url deny_extensions:应忽略的扩展名值或列表。如果没有给出,它将默认为 scrapy.linkextractors.IGNORED_EXTENSIONS 改变在2.0版本:IGNORED_EXTENSIONS现在包括 7z,7zip,apk,bz2,cdr,dmg,ico, iso,tar,tar.gz,webm,和xz。 就是说文件扩展名为这里面的内容的时候,将被排除 restrict_xpaths:是一个 XPath(或 XPath 的列表),它定义了响应中应从中提取链接的区域。如果给定,则只会扫描那些 XPath 选择的文本以获取链接。 restrict_css:一个 CSS 选择器(或选择器列表),它定义了响应中应从中提取链接的区域。具有与restrict_xpaths相同的行为; restrict_text:提取出来的链接,必须匹配这里的正则表达式(一个或选择器列表),才被提取。如果没给定,则匹配所有内容(我为什么不直接在上面给定链接呢) tags:提取的链接是否考虑标签(默认值为:a标签,和area标签) attrs:在提取链接时考虑的属性,或者属性列表(仅适用于tags 参数中指定的那些标签)。默认为('href',) unique ( bool ) – 是否应将重复过滤应用于提取的链接。( 将当前链接用到的规则,继续用到提取到的链接上 ) strip:是否从提取的属性中去除字符串 process_value:一个函数,它接收从标签中提取的每个值和扫描的属性,并且可以修改该值并返回一个新的值,或者None完全忽略该链接。 如果未给出,则process_value默认为。lambda x : x# 例如,要从此代码中提取链接: <a href = "javascript:goToPage('../other/page.html'); return false">Linktext</a> # 您可以在以下功能中使用process_value: def process_value(value): m = re.search("javascript:goToPage\('(.*?)'", value) if m: return m.group(1)
Lxml 链接提取器的使用
from scrapy.linkextractors import LinkExtractor LinkEx_List = LinkExtractor( # ·············· # 这里按上面的规则进行自定义规则 ).extract_links(response) # 仅返回与传递给__init__链接提取器方法的设置匹配的链接。 重复链接被省略。
get 和 getall 方法返回值
- .get(default=’not-found’)
- .get 和.getall 方法默认在没有取到值的时候会返回 None,default 可以修改为指定内容
- 对应老版本的方法:extract_first(),以及 extract()
获取属性:attrib[‘href’]
- 获取属性不只可以用 xpath 的@src 方法
- 上面方法在获取多条属性的时候需要多次定位 xpath
- 可以使用.attrib[‘href’]
- 在定位到一个元素后调用方法取第一个匹配到属性的值
- 比如上面的就是定位到第一个匹配的 href 属性
item 简单介绍
- item 可以把他看作是 Python 的字典进行操作
- one_field = Field():使用以下语句进行声明
- fields:可以使用这个属性,将 item 的所有声明的字段进行输出(而不是已赋值的)
- 可以使用各种字典方法进行操作
# 将会拿取item中的name属性,如果name未赋值,将返回第二个内容 item.get('name', 'not name') # 通过in属性判断是否存在于item已赋值的属性中 'name' in item # 通过in fields 属性,判断指定属性是否在item已定义的属性中 'name' in item.fields # 通过keys获取所有键 item.keys() # 通过values()获取所有值 item.values() # 通过items()获取键值对列表 item.items() # 你还可以直接从一个字典实例化item i = item({'name': 'nana', 'age': '18'})
- 现在
item支持以下方式书写 就会有代码提示@dataclass class CustomItem: one_field: str another_field: int
item(Item Loader 装载机的使用)
- 正常的 item 使用就是以 Python 字典的形式先找到数据再赋值
- scrapy 提供了物品装载机,使用 itemloader 可以方便的填充 item
- from scrapy.loader import ItemLoader
- item = ItemLoader(item=SpiderItem(), response=response)
item 提供以下三种方式进行赋值
item.add_xpath('name', '/p/div') item.add_css('name', 'p#id') item.add_value('name', 'value')
- itemloader 是
允许对两个相同的属性进行赋值的,它知道该怎么处理注意最后 yield 的时候需要调用 yield item.load_item()方法
重复筛选器:
- 操作就是增加一个集合,判断一下存在集合内就不进行处理。
- 使用的是
ItemAdapter:与数据容器对象交互的包装类。它提供了一个通用接口来提取和设置数据,而无需考虑对象的类型。- 将
Item转换一下再进行比较。无需考虑对象的类型。from itemadapter import ItemAdapter from scrapy.exceptions import DropItem class DuplicatesPipeline: def __init__(self): self.ids_seen = set() def process_item(self, item, spider): adapter = ItemAdapter(item) if adapter['id'] in self.ids_seen: raise DropItem(f"Duplicate item found: {item!r}") else: self.ids_seen.add(adapter['id']) return item
在管道中直接存储 item 到本地 Json 文件
import json from itemadapter import ItemAdapter class JsonWriterPipeline: def open_spider(self, spider): self.file = open('items.jl', 'w') def close_spider(self, spider): self.file.close() def process_item(self, item, spider): line = json.dumps(ItemAdapter(item).asdict()) + "\n" self.file.write(line) return item
scrapy shell url
- 非常推荐在开发调试期间使用 shell 进行调试,可以极大节省开发时间
- 详见:https://docs.scrapy.org/en/latest/topics/shell.html
- 反正我是不喜欢用 = = !
Cookies
- 在 scrapy 中要为请求设置 cookie 尽量按要求设置,不要直接加在 Headers 里
- 在 scrapy 请求中专门有一个属性 Request.cookies 用于设置请求的 cookie
- cookies 的两种请求方式:(第二种允许自定义 cookies)
- scrapy 默认是保留 cookie,下次的请求再次带上之前的 cookie
- 若要发 cookie 但不保存可以指定:meta={‘dont_merge_cookies’: True}
# 请求cookie。这些可以以两种形式发送。 # 1.使用字典: request_with_cookies = Request(url="https://www.example.com", cookies={'currency': 'USD', 'country': 'UY'}) # 2.使用字典列表: request_with_cookies = Request(url="https://www.example.com", cookies=[{'name': 'currency', 'value': 'USD', 'domain': 'example.com', 'path': '/currency'}]) # 后一种形式允许自定义cookie的domain和path属性。这仅在为以后的请求保存cookie时才有用。 # 当某些站点返回cookie(在响应中)时,这些cookie存储在该域的cookie中,并将在以后的请求中再次发送。这是任何常规Web浏览器的典型行为。 # 要创建不发送存储的cookie和不存储收到的cookie的请求,请将request.meta中的dont_merge_cookies键设置为True。 # meta={'dont_merge_cookies': True} # 发送手动定义的cookie并忽略cookie存储的请求示例: Request( url="https://www.example.com", cookies={'currency': 'USD', 'country': 'UY'}, meta={'dont_merge_cookies': True}, )
Cookie 转换
- 在浏览器中复制的 cookie 无法直接给 Scrapy 使用,需要进行转换,参照以下代码
- 以下代码我是在 cookie 中间件中使用的
# 将浏览器复制的cookie修改在这 cookie = '' request.cookies = {l.split("=", 1)[0]: l.split("=", 1)[1] for l in cookie.split("; ")} request.headers['User-Agent'] = self.UserAgent.randomScrapy 是否自动管理 cookie? 是的,Scrapy 接收并跟踪服务器发送的 cookie,并在后续请求中将它们发送回,就像任何常规的 Web 浏览器一样。
一个爬虫多个 Cookie
- 有可能出现下面这种情况。
- 一个网页可能封的比较严重,一个用户去请求多次就会被封。
- 中间如果间隔长一点,就不会了,那么怎么在一个爬虫中切换不同的 Cookie 呢。
- 用到 cookijar
以下摘自 Scrapy 文档
- 每个蜘蛛有多个 cookie 会话支持通过使用 请求元键为每个蜘蛛保留多个 cookie 会话。
- 默认情况下,它使用单个 cookie jar(会话),但您可以传递标识符以使用不同的标识符。cookiejar
例如
for i, url in enumerate(urls): yield scrapy.Request(url, meta={'cookiejar': i}, callback=self.parse_page)
- 请记住,元键不是“粘性”的。您需要在后续请求中继续传递它。
def parse_page(self, response): # do some processing return scrapy.Request("http://www.example.com/otherpage", meta={'cookiejar': response.meta['cookiejar']}, callback=self.parse_other_page)
- 使用 cookiejar 就可以为你的一个爬虫,有多个身份,再加上代理,就可以最大限度的防止封禁的情况出现。
POST 与模拟登录与 JSON 请求
- FormRequest 通过 HTTP POST 发送数据
yield FormRequest(url="https://www.example.com/post/action", formdata={'name': 'name', 'password': 'pwd'}, callback=self.parse)
- FormRequest.from_response() 模拟用户登录
yield scrapy.FormRequest.from_response( response, formdata={'username': 'john', 'password': 'secret'}, callback=self.after_login )
- 首先需要的是一个登录页面的 response,然后 formdata 的键代表着登录用户名和密码框的 name 属性名
- 不过在正常情况下都不会用这种方式,正常的登录情况都是非常多变的
- 发送 JSON POST 请求
- 就是发送的数据不同。
from scrapy.http import JsonRequest data = { 'name1': 'value1', 'name2': 'value2', } yield JsonRequest(url='https://www.example.com/post/action', data=data)
文件下载管道和图片下载管道
文件下载管道
# 需要导入的文件管道头 from scrapy.pipelines.files import FilesPipeline # 创建一个类继承自文件下载管道(记得在配置文件中开启保存位置配置,要不然无法生效) class MyFilesPipeline(FilesPipeline): # 重写这个方法,通过传递进来的item获取url,重新提交给管道安排下载 def get_media_requests(self, item, info): # 这里不管你中间怎么写,最终只要返回一个带图片下载地址的列表即可 return [Request(u) for u in item['image_urls']] # 在这通过request,拿到链接里面的信息进行重命名,当然,你也可以通过item拿取 def file_path(self, request, response=None, info=None, *, item=None): # 这里不管你怎么写,最终返回是一个地址就行,这里的地址是相对地址,相对于当前工作目录下,配置文件中设置的保存地址 return join(item['file_name'][0], image_name + '.' + image_format) # 当项目完成自动调用此方法,将item传递给接下去的管道 def item_completed(self, results, item, info): return item
- 然后配置文件中修改:
FILES_STORE = '这里改为下载文件保存文件夹名' FILES_EXPIRES = 90 # 单位为天,避免重复下载系统的文件夹过期时间 # 再开启管道中间件 ITEM_PIPELINES = { 'Myspider.pipelines.MyFilesPipeline': 301, }
- 图片管道中间件的使用和文件类似
- 继承修改自:from scrapy.pipelines.images import ImagesPipeline
- 配置文件修改为:IMAGES_STORE = ‘这里改为下载图片保存文件夹名’
- 文件过期时间为:IMAGES_EXPIRES = 90
- 管道中间件改为你的中间件名
- 注意事项:
开启管道要开启的名字是你创建的类名,不是继承的类名
用图片管道下载的图片会自动被压缩,不知道为什么(用文件下载管道下载的图片就是原始图片)
- 从2.8.0 版本开始
Scrapy不会再重新编码图片通道 也就是不会降低图片像素了但图片下载管道可以自动生成缩略图,并且可以过滤掉图片小于指定尺寸的
# 在配置中修改以开启缩略图生成 IMAGES_THUMBS = { # 需要更多尺寸只要一直增加即可 'small': (50, 50), 'big': (270, 270), # 上面中的键,会在下面中的size_name中出现 } # 当您使用此功能时,图像管道将使用以下格式创建每个指定大小的缩略图: # <IMAGES_STORE>/thumbs/<size_name>/<image_id>.jpg # 当图片小于指定尺寸的时自动过滤 IMAGES_MIN_HEIGHT = 110 IMAGES_MIN_WIDTH = 110 # 当图片宽高有一项不满足,就会被丢弃。
解除 scrapy 下载文件限制
- DOWNLOAD_MAXSIZE
- 默认值:1073741824(1024MB)
- 下载器将下载的最大响应大小(以字节为单位)。
- 如果你想禁用它设置为 0
下载图像直接上传到 FTP 服务器
- 还可以执行亚马逊存储,谷歌云存储
- FILES_STORE 与 IMAGES_STORE 可以指向 FTP 服务器。Scrapy 会自动将文件(图片)上传到服务器。
- FILES_STORE 并 IMAGES_STORE 应以下列形式之一书写:
- ftp://username:password@address:port/path
- ftp://address:port/path
文件过期
- Pipeline 避免下载最近下载的文件。可以调整此保留延迟,
- 保留已下图片的时间(在时间内不会再次下载相同的图片)
- 并不会在到期后自动删除图片
- 默认都是 90 天
- FILES_EXPIRES = 30
- 图片过期时间
- IMAGES_EXPIRES = 30
统计信息收集
- Scrapy 提供了一种方便的工具来以键/值的形式收集统计信息,其中值通常是计数器。
- 该工具称为 Stats Collector,可以通过 Crawler API 的 stats 属性访问
在你需要统计信息的位置,定义一个类,通过 scrapy 提供的 from_crawler 进行关联,语法如下。
class ExtensionThatAccessStats: # 下面的类属性会传递给类初始化方法进行调用 def __init__(self, stats): self.stats = stats # 设置需要统计的值 stats.set_value('hostname', socket.gethostname()) # 增加统计的值 stats.inc_value('custom_count') # 当值大于当前值时才设置值 stats.max_value('max_items_scraped', value) # 当小于当前值才设置值 stats.min_value('min_free_memory_percent', value) # 获取统计的值 stats.get_value('custom_count') # 获取所有统计的值 stats.get_stats() # 返回值是类本身,通过crawler访问stats属性 @classmethod def from_crawler(cls, crawler): return cls(crawler.stats)
设置 IPV6
DNS_RESOLVER
2.0 版中的新功能。
默认: ‘scrapy.resolver.CachingThreadedResolver’
用于解析 DNS 名称的类。默认 scrapy.resolver.CachingThreadedResolver
支持通过 DNS_TIMEOUT 设置为 DNS 请求指定超时,但仅适用于 IPv4 地址。
Scrapy 提供了一个替代的解析器, scrapy.resolver.CachingHostnameResolver 支持 IPv4/IPv6 地址
但不考虑 DNS_TIMEOUT 设置。也就是说这样做后,您将无法为 DNS 请求设置特定的超时时间
在浏览器中打开 response
- from scrapy.utils.response import open_in_browser
- open_in_browser(response)
禁用失败重试 or 设置下载超时
- scrapy 默认失败会进行重试:关闭进行配置
- 要禁用重试,请使用:
- RETRY_ENABLED = False
- 失败重试配置
# 打开重试(默认值) RETRY_ENABLED = True # 重试次数 RETRY_TIMES = 3 # 元键重试次数(这个也是设置重试次数,但这个优先级比RETRY_TIMES高。) max_retry_times = 3 # 超时时间(访问超时,下载超时) DOWNLOAD_TIMEOUT = 3
禁用重定向
- 要禁用重定向,请使用:
- REDIRECT_ENABLED = False
- 允许重定向最大次数,程序有限性,默认: 20
- REDIRECT_MAX_TIMES=20
允许管道重定向
- 默认情况下,媒体管道忽略重定向,即对媒体文件 URL 请求的 HTTP 重定向将意味着媒体下载被视为失败。
- 要处理媒体重定向,请将此设置设置为 True:
- MEDIA_ALLOW_REDIRECTS = True
- 如果不改,二次跳转的页面也无法下载
自动限速与自动并发扩展
- 这是根据 Scrapy 服务器和您正在爬行的网站的负载自动限制爬行速度的扩展。
- 1.对网站更好,而不是使用默认的零下载延迟
- 2.自动将 Scrapy 调整到最佳爬行速度,因此用户无需调整下载延迟即可找到最佳的下载延迟。用户只需要指定它允许的最大并发请求数,其余的由扩展来完成。
- 配置详见:链接: link.
AUTOTHROTTLE_ENABLED = True # 是否启用扩展 默认: False AUTOTHROTTLE_START_DELAY = 5.0 # 初始下载延迟 默认:5.0 # (秒) AUTOTHROTTLE_MAX_DELAY = 60.0 # 允许的最大延迟 默认:60.0 # (秒) # 默认:1.0 # (秒) 数值越低,对远程网站越友好,相对的速度越慢。 AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0 # 并发到远程网站的平均请求数 AUTOTHROTTLE_DEBUG = False # 开启扩展debug模式 默认:False
增加 Twisted IO 线程池最大大小
- 目前 Scrapy 使用线程池以阻塞方式进行 DNS 解析。使用更高的并发级别,爬行可能会很慢,甚至无法达到 DNS 解析器超时。增加处理 DNS 查询的线程数量的可能解决方案。将更快地处理 DNS 队列,从而加快建立连接和整体爬行的速度。
- 要增加最大线程池大小,请使用:
REACTOR_THREADPOOL_MAXSIZE = 20
缓存中间件
- 将所有爬虫获取到的网页缓存在本地,下次访问系统网页将会直接提取本地的网页信息 ( 缓存未超时的情况下 )
# 缓存中间件 # 是否启用缓存(默认为:False) HTTPCACHE_ENABLED = True # 缓存过期时间 # 超过此时间的缓存请求将被重新下载。如果为0,缓存的请求将永远不会过期。 HTTPCACHE_EXPIRATION_SECS = 3600 # 用于存储(低级)HTTP 缓存的目录。如果为空,HTTP 缓存将被禁用。如果给出了相对路径,则采用相对于项目数据目录的路径。 HTTPCACHE_DIR = 'httpcache' # 不要使用这些 HTTP 代码缓存响应。(当出现下面的状态码的时候,不缓存响应) HTTPCACHE_IGNORE_HTTP_CODES = [] # 如果启用,将使用 gzip 压缩所有缓存数据。此设置特定于文件系统后端。 HTTPCACHE_GZIP = False # 如果启用,将无条件缓存页面。 HTTPCACHE_ALWAYS_STORE = False # 如果启用,缓存中未找到的请求将被忽略而不是下载。 HTTPCACHE_IGNORE_MISSING = False
scrapy 信号机制
from scrapy import signals @classmethod def from_crawler(cls, crawler, *args, **kwargs): spider = super(PaSpider, cls).from_crawler(crawler, *args, **kwargs) crawler.signals.connect(spider.spider_closed, signal=signals.spider_opened) return spider def spider_closed(self, spider): print('123123123123')
- 上面通过 crawler.signals.connect 将 spider_closed 和 signals.spider_opened 信号进行连接
- 连接后触发信号将会执行函数
- 信号列表:scrapy
- engine_started = object()
- engine_stopped = object()
- spider_opened = object()
- spider_idle = object()
- spider_closed = object()
- spider_error = object()
- request_scheduled = object()
- request_dropped = object()
- request_reached_downloader = object()
- request_left_downloader = object()
- response_received = object()
- response_downloaded = object()
- headers_received = object()
- bytes_received = object()
- item_scraped = object()
- item_dropped = object()
- item_error = object()
from_crawler 核心 API
- Scrapy API 的主要入口点是 Crawler 对象,通过类方法传递给扩展。该对象提供对所有 Scrapy 核心组件的访问,它是扩展访问它们并将其功能挂钩到 Scrapy 的唯一方法。from_crawler
- 重写这方法注意事项:
- 需要返回一个实例对象
- 返回实例对象括号里面的参数,是会进入初始化方法init的
scrapy 自带异步发送邮件
1.配置文件中添加信息(推荐)
MAIL_FROM = '@qq.com' MAIL_HOST = 'smtp.qq.com' MAIL_PORT = 587 MAIL_USER = '@qq.com' MAIL_PASS = '密钥'2.直接实例化一个带信息的请求(可选)
mailer = MailSender( smtphost='smtp.qq.com', mailfrom='@qq.com', smtpuser='@qq.com', smtppass='密钥', smtpport=587, )3.发送邮件
attach_name = "1.txt" # 附件名 mimetype = '.txt text/plain' # 附件类型 file_object = open(r'1.txt', 'rb') # 二进制读取数据 body = '主体内容'.encode('utf-8') subject = '标题' charset = 'utf-8' attachs = [(attach_name, mimetype, file_object)] # 附件信息 cc = '@qq.com' # 抄送显示的url mailer.send(to=["@qq.com"], subject=subject, body=body, charset=charset, cc=cc, attachs=attachs, mimetype=mimetype)
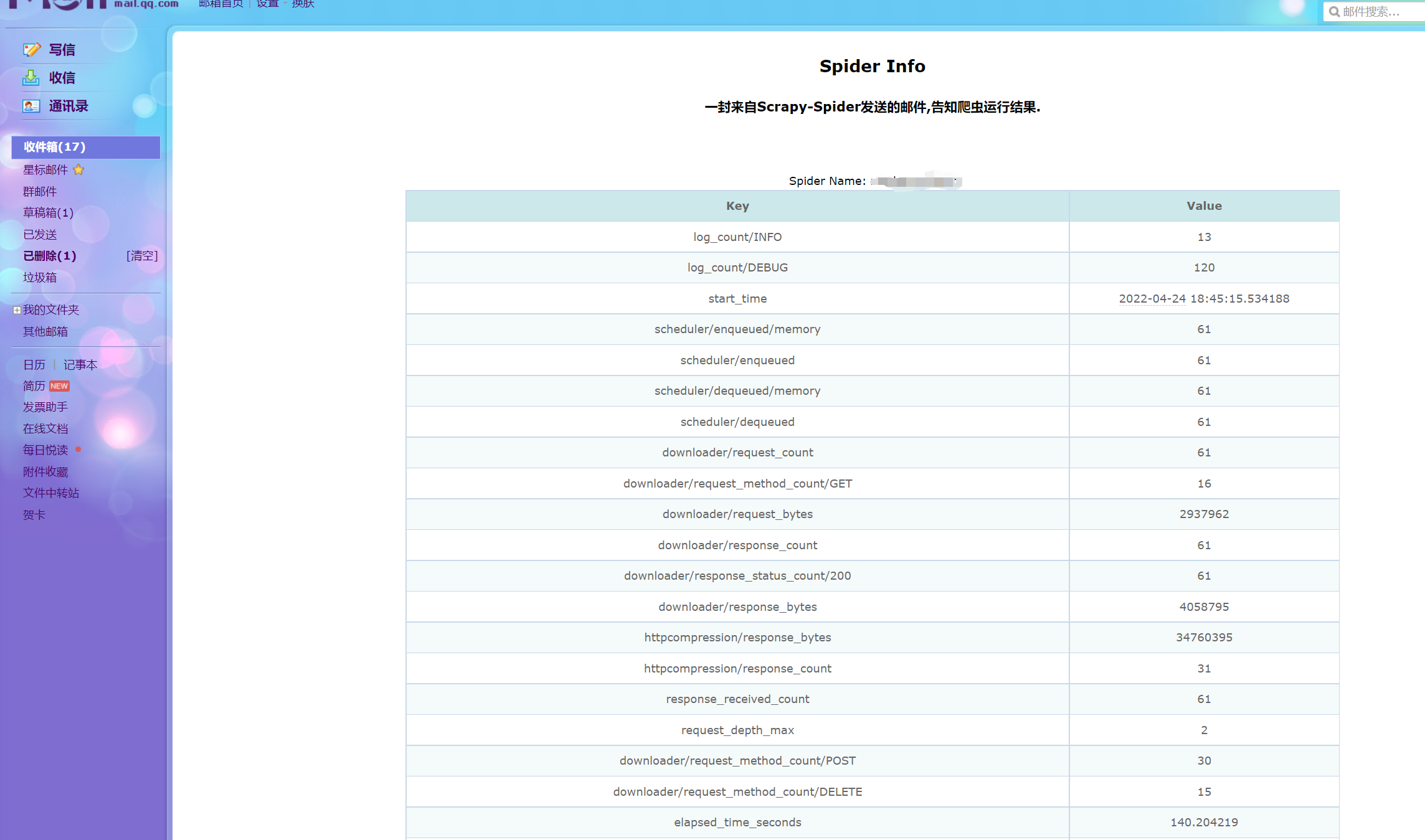
邮件模板
- 使用以下模板可以让你收到漂亮的统计邮件信息
import datetime from scrapy import signals from scrapy.exceptions import NotConfigured from scrapy.crawler import Crawler from scrapy.mail import MailSender from scrapy.spiders import Spider class SendMailExtensions: @classmethod def from_crawler(cls, crawler: Crawler): # 当不存在 EMAIL_HTML_TEMPLATES 属性的时候,不启动邮件发送插件 if not crawler.settings.get("EMAIL_HTML_TEMPLATES", None): raise NotConfigured # 绑定事件,在每个爬虫结束的时候,发送邮件 s = cls() crawler.signals.connect(s.spider_closed, signal=signals.spider_closed) return s def spider_closed(self, spider: Spider): spider.logger.info('Spider closed SendMail: %s' % spider.name) mailer = MailSender( smtphost='smtp.qq.com', mailfrom='@qq.com', smtpuser='@qq.com', smtppass='', smtpport=587, ) # 获取统计信息 stats_dict = spider.crawler.stats.get_stats() # Scrapy 时间是错的,需要自己增加 stats_dict['start_time'] += datetime.timedelta(hours=8) stats_dict['finish_time'] += datetime.timedelta(hours=8) table_body = ''.join([f"<tr><td>{k}</td><td>{v}</td></tr>" for k, v in stats_dict.items()]) html_body = spider.settings['EMAIL_HTML_TEMPLATES'].replace("<replace_head>", "Spider Name: " + spider.name).replace("<replace_body>", table_body) subject = 'Spider-' + spider.name to = [ "*@qq.com" ] mailer.send(to=to, mimetype='text/html', subject=subject, body=html_body)
- 配置文件中需要有以下内容 (不存在则插件失效)
EMAIL_HTML_TEMPLATES = """<style>table{border-collapse:collapse;margin:0 auto;text-align:center;}table td,table th{border:1px solid#cad9ea;color:#666;height:30px;}table thead th{background-color:#CCE8EB;width:100px;}table tr:nth-child(odd){background:#fff;}table tr:nth-child(even){background:#F5FAFA;}</style><table width="1000px"class="table"style="font-size: 12px"><caption><h2>Spider Info</h2><h3>一封来自Scrapy-Spider发送的邮件,告知爬虫运行结果.</h3><br><br><replace_head><br></caption><thead><tr><th>Key</th><th>Value</th></tr></thead><replace_body></table>"""
- 上面中用了特定字符作为占位符,然后在插件中生成表格之后替换掉,发送过去会被解析为 HTML
- 你将在爬虫完成之后,收到以下效果的执行图。
HTTP/2 协议
- 现在有些网站反爬虫是直接拒绝所有非 HTTP/2 的请求。
- requests 还不支持 HTTP/2 请求
- 在 scrapy 中开启 HTTP/2 协议请求方式:
# 默认HTTPS处理程序使用HTTP/1.1。要使用HTTP/2更新DOWNLOAD_HANDLERS修改为如下: DOWNLOAD_HANDLERS = { 'https': 'scrapy.core.downloader.handlers.http2.H2DownloadHandler', } # 实验性功能,未来可能直接无法使用
深入优先和广度优先
默认情况下,深度优先(DFO),这种操作在大多数情况下更方便。
如果你希望广度优先,您可以通过设置以下设置来完成此操作:
这可能会降低爬行的速度。
DEPTH_PRIORITY = 1 SCHEDULER_DISK_QUEUE = 'scrapy.squeues.PickleFifoDiskQueue' SCHEDULER_MEMORY_QUEUE = 'scrapy.squeues.FifoMemoryQueue'
获取网页返回的 HTML 页面
- scrapy fetch https://www.baidu.com > response.html
response 请求以及响应对象方法
配置文件各属性作用
2023-03-06 更新
- 如果你想要在
vscode启动 Scrapy 可以用下面的配置文件
{
"version": "0.1.0",
"configurations": [
{
"name": "Python: Launch Scrapy Spider",
"type": "python",
"request": "launch",
"module": "scrapy",
"args": [
"runspider",
"${file}"
],
"console": "integratedTerminal"
}
]
}- 现在新版本支持更多的异步 比如
process_spider_outputparse都支持异步 - 大更新 2.8.0 现在 scrapy 的图片下载管道 不会再重新编码 就是说 现在下载图片不会降低图片像素了
- 新的
item书写形式 有代码提示