from_crawler
- 今天复习 scrapy 的时候再次看到这位兄弟(姐妹)
- 半年之前似懂非懂的理解了这个东西的作用,现在回头来看,还是不懂.
- 在这写一篇笔记,进行记录一下。
首先来看看官方文档是怎么解释这个的
- Scrapy API 的主要入口点是
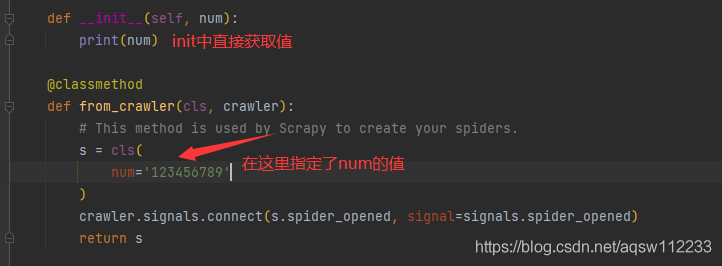
Crawler对象,通过类方法传递给扩展。该对象提供对所有 Scrapy 核心组件的访问,它是扩展访问它们并将其功能挂钩到 Scrapy 的唯一方法。from_crawler看看这个兄弟在代码中是怎么样的
from scrapy import signals ...... @classmethod def from_crawler(cls, crawler): # This method is used by Scrapy to create your spiders. s = cls() crawler.signals.connect(s.spider_opened, signal=signals.spider_opened) return s
上面代码是在中间件中复制的
@classmethod:修饰符,不需要实例化,第一个参数是类本身,第二个参数是 crawler
- crawler:这个参数就是上面那句话解释的入口 API
- 想想,当我们写了一个类,这个类又没有继承
Scrapy的类,那么这个类怎么就可以连接 Scrapy 的核心内容呢?
- 就是通过这个方法,其中的
crawler就是操作scrapy一切内容的核心- 在你修改好之后,将他在配置文件中启动,
Scrapy将会进行操作。- 这个方法有点类似 Python 中的new,在最后返回的 cls()中的参数,会被传递给这个类的init > >
- 第二句话的意思就:
- 将这个类的 spider_opened 方法和 scrapy 爬虫开始的信号进行绑定,当爬虫开始的时候,就会调用这个类的 spider_opened 方法。
通过 dir 看看 crawler 方法 crawler 方法解释
spider
- 这个就是当前运行的爬虫
- 并且可以通过 spider 传递值
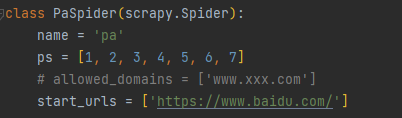
- 比如我在爬虫开始的时候对 spider 设置了一个列表,我希望传递给中间件和管道
- 现在当前的 spider 中已经有 ps 这个属性,那在中间件中就可以获取
>
>
- 这是在构造爬虫时提供的蜘蛛类的一个实例,它是在
crawl()方法中给出的参数之后创建的。- 注意这个
crawl在中间件中可以直接crawler.spider.name取到运行的爬虫名字
- 但是在
插件中,无法获取,需要改为crawler.spidercls.name

settings
- 官方解释就是
- 此爬虫的设置管理器。扩展和中间件使用它来访问此爬虫的 Scrapy 设置。
- 注意这里只是获取,使用方式和字典一样
- 比如获取日志等级
crawler.settings['LOG_LEVEL']
signals 信号
- 官方解释:
- 此爬虫的信号管理器。扩展和中间件使用它来将自己挂钩到 Scrapy 功能中。
- 使用方法和上面一直
- 通过 signals 中的 connect 进行连接
- 后面的 signal=signals.spider_opened 需要导入 scrapy 信号包
from scrapy import signals crawler.signals.connect(s.spider_opened, signal=signals.spider_opened)
- 将爬虫的 spider_opened 方法和 spider_opened 信号进行绑定,当信号触发之后自动调用 spider_opened 方法
- 信号有许多种,但无法自定义信号(差劲…)
stats 统计收集器
- 一个用于获取爬虫运行期间的各项统计信息,并且可以自定义设置某些值,以及数值增加条件,具体可以看上面。
engine 引擎
- 核心部件之一,通过这个属性,可以操作 引擎的 启动,暂停,恢复,停止。
spider.crawler.engine.pause() # 暂停引擎 spider.crawler.engine.unpause() # 恢复引擎 spider.crawler.engine.stop # 停止引擎
- 引擎一旦停止,所有请求将不再操作。
crawl
- 通过给定的参数来创建蜘蛛,创建完毕之后,将引擎设为启动。
- 这个方法实例之后,类将可以操作
Scrapy的核心内容
stop
- 开始当前爬虫的正常停止程序,并返回当爬虫停止时触发的延迟..



